

하아찡
크롤링 네이버 뉴스 긁어오기 본문
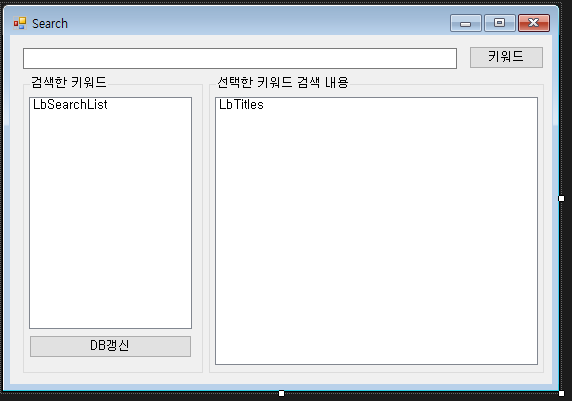
기본구성은
검색 키워드 입력창 / 입력했던 키워드 LISTBOX / 해당 키워드로 검색된 타이틀 출력해주는 LISTBOX
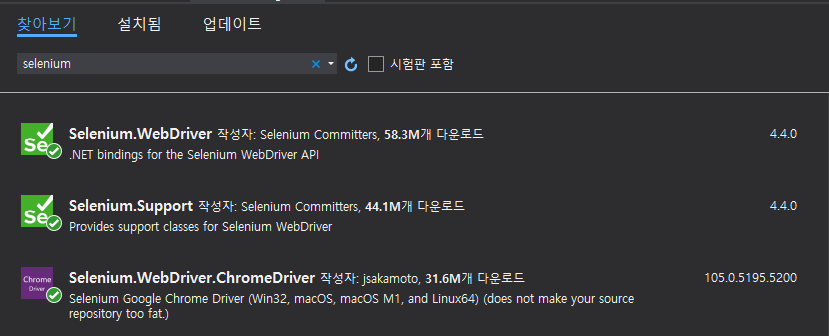
프로젝트 -> Nuget 패키지 추가에서 아래 이미지 해당요소들을 추가해준다.
(저는 크롬을 사용하여 크롬드라이브로 받았습니다.)
using 추가
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using OpenQA.Selenium.Support.UI;
Selenium 드라이브 셋팅
private void ChromeDriverSetting()
{
var driverService = ChromeDriverService.CreateDefaultService();
var options = new ChromeOptions();
//options.AddArgument("headless");//브라우저 비활성화
options.AddArgument("disable-gpu");
options.AddArgument("--mute-audio");
driver = new ChromeDriver(driverService, options);
}
여기까지 작업을 완료하시면 아래 이미지와 같은 콘솔과 크롬창이 켜집니다.
추후 이창을 안보이게하고싶을때 셋팅에서 headless 주석을 풀면됩니다.

네이버 검색 URL
네이버 뉴스에서 특정 키워드를 검색해서 가져오기 위해 URL 하나가 필요한데
string SerchUrl = "https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query=";해당 쿼리 뒤에 키워드를 붙여서 검색하면 내가 입력한 키워드로 네이버 뉴스로 검색해짐.
Element 찾기
Element 찾는 방식은 여러가지가있는데 저는 ClassName, Xpath, TagName을 사용했습니다.
목록이 여러개 있을경우에는 해당 뉴스 목록을 묶어주는 div 에 class or id 값을 하나 찾아줍니다.

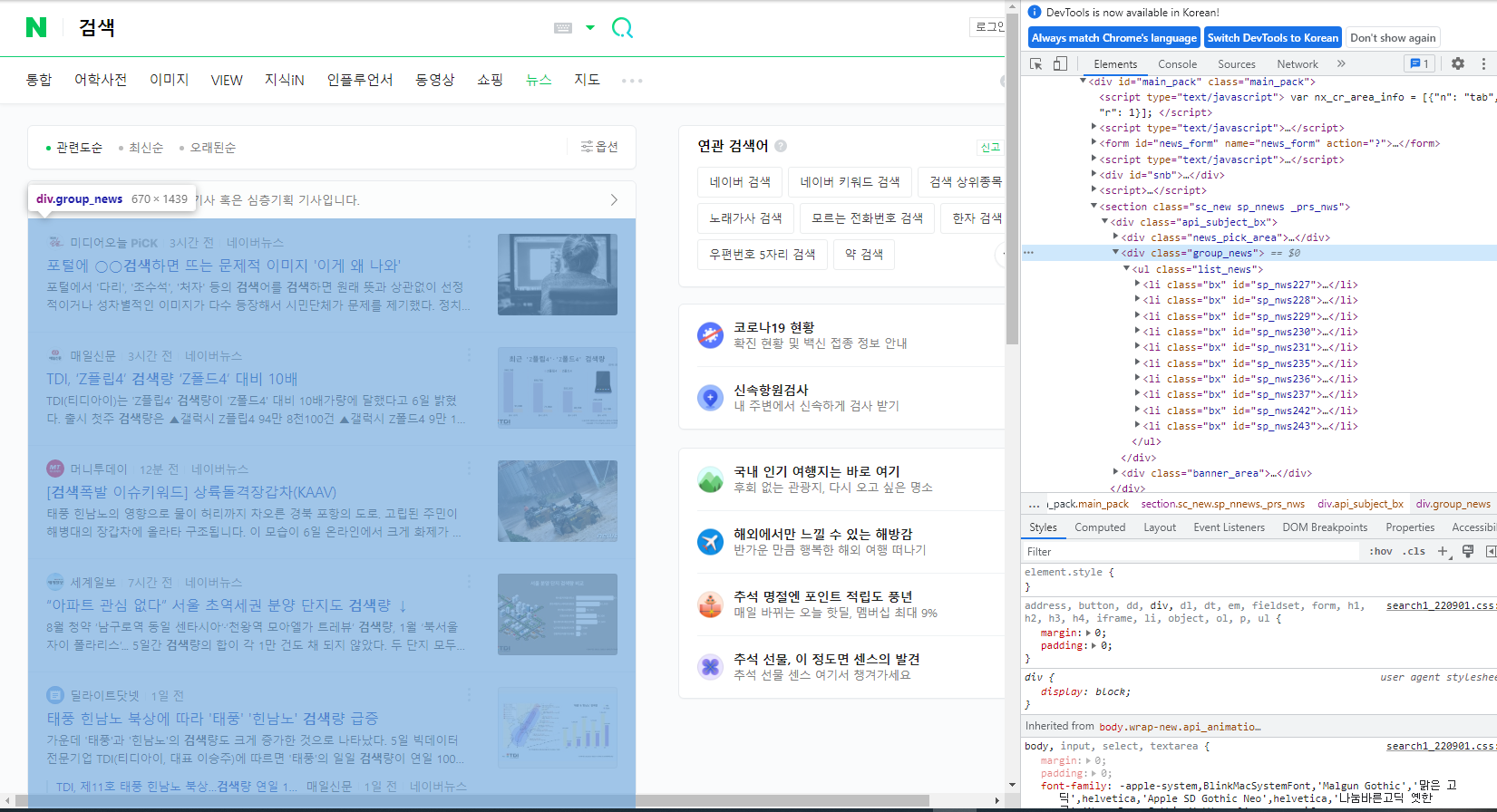
위에 사진과 같이 클래스값을 찾았을 경우 클래스로 해당 Element를 찾아도 되고, 해당부분을 우클릭해서 XPath값으로 구해도 상관없습니다.

구해진 XPaht값은
//*[@id="main_pack"]/section/div/div[2] 이며, 이걸 가지고 해당 목록을 읽어옵니다.
driver.Navigate().GoToUrl(SerchUrl + TxtKeyword.Text);
WebDriverWait wait = new WebDriverWait(driver, TimeSpan.FromSeconds(1));
var ui = driver.FindElement(By.XPath("//*[@id=\"main_pack\"]/section[1]/div/div[2]/ul"));
목록을 구했으니 해당 목록안에 있는 리스트 값을 가져오기위해 해당 블럭을 나눠준 li Class값을 찾아 반복문을 사용해줍니다.
foreach (var view in ui.FindElements(By.ClassName("bx")))
{
var _title = view.FindElement(By.ClassName("news_tit"));
//추후 사이트이름으로 특정 뉴스사만 제외하고 저장할수있게 기능 추가예정. 22.09.06
string title = _title.Text;//기사제목
string sitename = view.FindElement(By.ClassName("thumb_box")).Text;//뉴스 홈페이지 이름
string href = _title.GetAttribute("href");//기사 링크
//DB에 데이터 저장
string query = $"INSERT INTO SEARCH(KEYWORD,TITLE,HREF,SITENAME) VALUES ('{TxtKeyword.Text}','{title.Replace("'","")}','{href}','{sitename}');";
ms.SendQuery(query);
}변수 ui는 해당 목록을 저장해둔 변수이며 그 변수에서 리스트를 찾기때문에 ui에서 FindElements를 사용합니다.
리스트가 여러개이기 때문에 FindElements를 사용했으며 단일일경우 s를 제거해줍니다.
여기까지 진행하면 해당 페이지에 있는 기사제목, 해당 기사 뉴스홈페이지, 기사링크 값을 저장할수 있습니다.
다음페이지 뉴스 내용 불러오기

해당 이미지에서 빨간박스 페이지 이동하는 버튼들이 존재함.
해당 박스값을 따와서 위에서 같이 리스트를 읽어오는 방식을 사용해서 다음페이지로 넘어간다.
var pagenumbers = driver.FindElement(By.ClassName("sc_page_inner")).FindElements(By.TagName("a"));
foreach (var page in pagenumbers)
{
if ((NowPage + 1) == Convert.ToInt32(page.Text))
{
Checknextpage = false;
//다음페이지로
NowPage++;
//해당페이지를 클릭으로 넘어가지않고 엔터로 넘어감.
//가끔씩 클릭오류가 발생하기때문에
page.SendKeys(OpenQA.Selenium.Keys.Enter);
break;
}
}
완성된 작업물

완성된 코드
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using OpenQA.Selenium.Support.UI;
using System.Collections.Generic;
using System;
using System.Windows.Forms;
namespace Crawling
{
public partial class Form1 : Form
{
ChromeDriver driver;
Mssql ms = new Mssql();
List<string> hrefs;//해당 사이트주소 저장
string SerchUrl = "https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query=";
public Form1()
{
InitializeComponent();
}
private void ChromeDriverSetting()
{
var driverService = ChromeDriverService.CreateDefaultService();
var options = new ChromeOptions();
string user_agent = "--user-agent=Mozilla/5.0 (Linux; Android 9; SM-G975F) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.83 Mobile Safari/537.36";
//options.AddArgument(user_agent);
//options.AddArgument("headless");//브라우저 비활성화
options.AddArgument("disable-gpu");
options.AddArgument("--mute-audio");
driver = new ChromeDriver(driverService, options);
}
private void BtnKeyword_Click(object sender, EventArgs e)
{
Serch();
}
private void Serch()
{
//현재 테스트용으로 10페이지까지만 검색.
int NowPage = 1;
driver.Navigate().GoToUrl(SerchUrl + TxtKeyword.Text);
while (true)
{
WebDriverWait wait = new WebDriverWait(driver, TimeSpan.FromSeconds(1));
var ui = driver.FindElement(By.XPath("//*[@id=\"main_pack\"]/section[1]/div/div[2]/ul"));
foreach (var view in ui.FindElements(By.ClassName("bx")))
{
var _title = view.FindElement(By.ClassName("news_tit"));
//추후 사이트이름으로 특정 뉴스사만 제외하고 저장할수있게 기능 추가예정. 22.09.06
string title = _title.Text;//기사제목
string sitename = view.FindElement(By.ClassName("thumb_box")).Text;//뉴스 홈페이지 이름
string href = _title.GetAttribute("href");//기사 링크
//DB에 데이터 저장
string query = $"INSERT INTO SEARCH(KEYWORD,TITLE,HREF,SITENAME) VALUES ('{TxtKeyword.Text}','{title.Replace("'","")}','{href}','{sitename}');";
ms.SendQuery(query);
}
var pagenumbers = driver.FindElement(By.ClassName("sc_page_inner")).FindElements(By.TagName("a"));
bool Checknextpage = true;//다음페이지가 없을경우 계속 True값을 유지하기때문에 자동으로 반복문이 나가진다.
foreach (var page in pagenumbers)
{
if ((NowPage + 1) == Convert.ToInt32(page.Text))
{
Checknextpage = false;
//다음페이지로
NowPage++;
//해당페이지를 클릭으로 넘어가지않고 엔터로 넘어감.
//가끔씩 클릭오류가 발생하기때문에
page.SendKeys(OpenQA.Selenium.Keys.Enter);
break;
}
}
if (NowPage > 10)
break;
if (Checknextpage)
break;
}
}
private void Form1_Load(object sender, EventArgs e)
{
ChromeDriverSetting();
}
private void TxtKeyword_KeyUp(object sender, KeyEventArgs e)
{
if (e.KeyCode == System.Windows.Forms.Keys.Enter)
{
Serch();
}
}
private void BtnDBRefresh_Click(object sender, EventArgs e)
{
LbSearchList.Items.Clear();
string query = "SELECT DISTINCT KEYWORD FROM SEARCH";
ms.ReadData(query);
while (ms.rdr.Read())
{
LbSearchList.Items.Add(ms.rdr["KEYWORD"].ToString());
}
ms.RdrClose();
}
private void LbSearchList_MouseDoubleClick(object sender, MouseEventArgs e)
{
//더블클릭했을때 선택된 아이템이 없을경우 종료
if (((ListBox)sender).SelectedIndex == -1)
return;
LbTitles.Items.Clear();
string query = $"SELECT * FROM SEARCH WHERE KEYWORD = '{LbSearchList.Items[LbSearchList.SelectedIndex].ToString()}'";
hrefs = new List<string>();
ms.ReadData(query);
while (ms.rdr.Read())
{
LbTitles.Items.Add(ms.rdr["TITLE"].ToString());//타이틀 출력
hrefs.Add(ms.rdr["HREF"].ToString());//링크값 저장
}
ms.RdrClose();
}
private void LbTitles_MouseDoubleClick(object sender, MouseEventArgs e)
{
//더블클릭했을때 선택된 아이템이 없을경우 종료
int index = ((ListBox)sender).SelectedIndex;
if ( index == -1)
return;
//해당 주소로 이동시킴
driver.Navigate().GoToUrl(hrefs[index]);
}
}
}
DB연동
using System.Data.SqlClient;
namespace Crawling
{
class Mssql
{
//서버연결 정보
SqlConnection con;
//DB 커맨드 보낼때
SqlCommand cmd;
//쿼리를 보낸후 데이터 받는 역할
public SqlDataReader rdr;
//접속할 서버 주소
string ServerIP;
//접속할 데이터베이스 이름
string DataBase;
//서버접속 아이디
string ServerID;
//서버접속 비밀번호
string ServerPW;
//********22.07.20 Mssql 외부접속 확인.********
public Mssql(string IP = "DB아이피주소", string DBbase = "CrawlingSerch", string ID = "DB아이디", string PW = "DB패스워드")
{
//서버 정보를 갱신함
ServerIP = IP;
DataBase = DBbase;
ServerID = ID;
ServerPW = PW;
con = new SqlConnection($"Server={ServerIP};database={DataBase};Uid={ServerID};Pwd={ServerPW}");
con.Open();
}
public object GetQueryCnt(string str)
{
//해당 쿼리문의 개수를 알아낸다
cmd = new SqlCommand(str, con);
return cmd.ExecuteScalar();
}
public void SendQuery(string str)
{
//전달받은 쿼리문을 보낸다.
cmd = new SqlCommand(str, con);
cmd.ExecuteNonQuery();
}
public void ReadData(string str)
{
//해당 쿼리를 보내 데이터를 읽어서 필요한부분에서 데이터 처리를해서 사용한다.
cmd = new SqlCommand(str, con);
rdr = cmd.ExecuteReader();
}
public void RdrClose()
{
//쿼리 보낸후 데이터를 다받고 처리후에 꺼주지않으면 에러가 났음.
rdr.Close();
}
public void ConClose()
{
//서버 연결 종료
con.Close();
}
}
}
테이블 구성(MSSQL)
Create Database CrawlingSerch;
CREATE TABLE SEARCH (
ID INT IDENTITY(1,1) NOT NULL ,/*인덱스*/
KEYWORD VARCHAR(50) NOT NULL,/*검색 키워드*/
TITLE VARCHAR(100) NOT NULL,/*해당뉴스 타이틀*/
HREF VARCHAR(300) NOT NULL,/*해당링크*/
SITENAME VARCHAR(100),/*뉴스사이트 이름*/
PRIMARY KEY(ID)
);
/*아직 미사용*/
CREATE TABLE SERACHDATA(
ID INT NOT NULL,
CONTENT VARCHAR(8000)
)
해당 기사 내용도 읽어오는 작업도 진행중임.
각 사이트마다 html 구성이 다르기때문에 작업이 많이 필요할 예정.
'C# > 크롤링' 카테고리의 다른 글
| [크롤링] 새창으로 핸들값 변경 (0) | 2022.08.30 |
|---|---|
| [크롤링] Selenium 네이버 로그인 자동입력방지 우회 (0) | 2022.08.30 |